
之前测试的VoxCPM2文章,感觉跟ElevenLabs还是有一定差距 NoOne,公众号:AI不硬核最新开源多语言TTS模型_VoxCPM2实测_从安装到测试全流程讲解
ElevenLabs官方指路:
https://elevenlabs.io/app/
所以我本来是没那么重视的。
但是我没关掉这个项目页面。
因为我又看了一眼,它的描述里写了三个字,桌面应用。
这玩意是个带图形界面的桌面App?
不是命令行,不是Docker容器,不是那个你得手搓Python环境才能跑的脚本。是下载,安装,打开,直接用。
而且支持Windows、macOS、Linux三个平台。
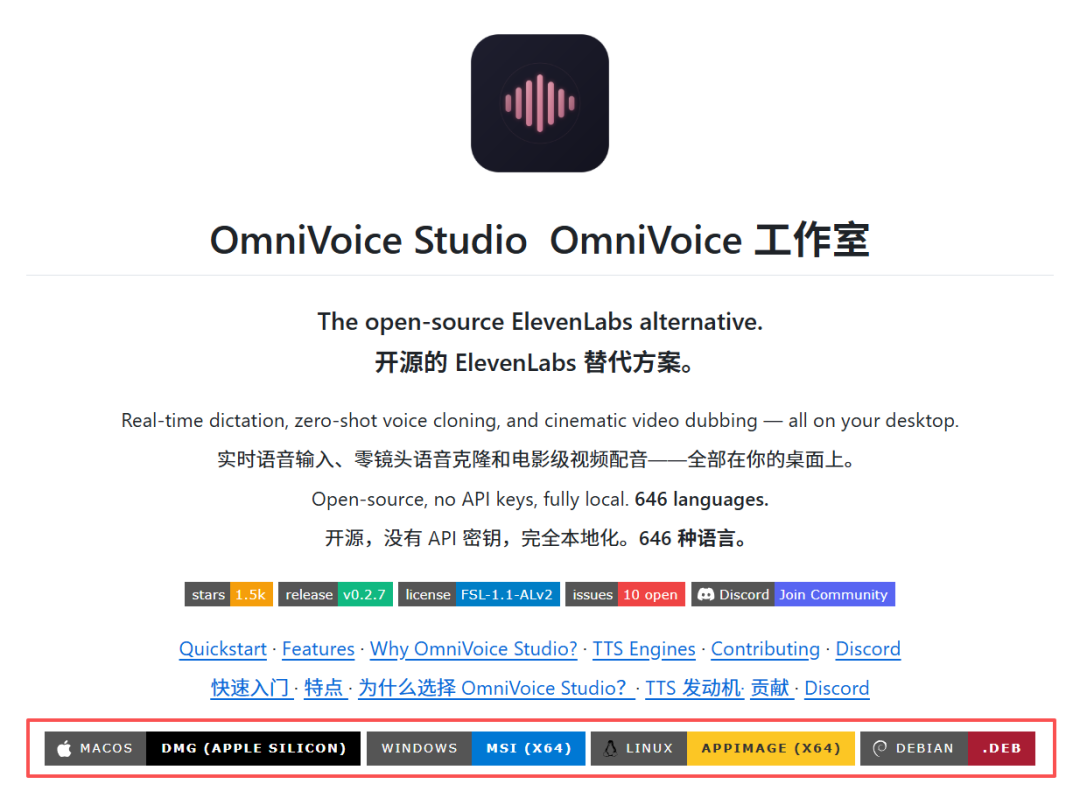
这下我就来兴趣了。把项目抬上来!
#项目指路:https://github.com/debpalash/OmniVoice-Studio
这个项目叫 OmniVoice Studio。
作者是一个印度的开发者,叫debpalash。他在4月9号把项目传上了GitHub,到现在也就一个多月的时间。
一个多月,1.5K Star,174个Fork。

这个速度放在AI工具这个赛道里,算得上爆发了。
而且你去看他的commit记录,140次提交,高频到离谱。最后一条commit是三天前,写了句「Post-refactor cleanup」,一看就是那种连重构完打扫战场的时间都要挤的人。
这种更新频率的项目,作者是真的在用心做。
那OmniVoice Studio到底能干什么呢。
咱们直接上手看看吧!
开始安装:
1.下载安装包
根据自己的电脑系统点击即可下载桌面应用,这里我是windows,所以选择的第二个,下载msi文件

2.安装包只有167.04MB,下载好之后打开就进入安装程序
C盘不够大的话记得安装到其它盘
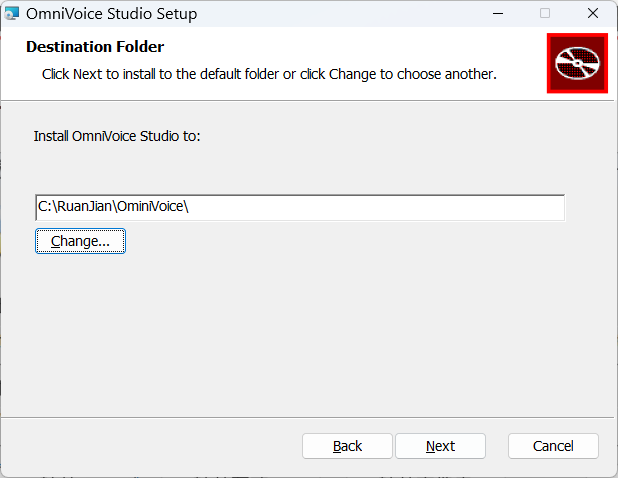
接着这里可以选择用中国镜像进行安装,也可以默认让它自动选择,然后就会不断拉取文件安装啦包括环境依赖也会自动安装,全程不用输入什么命令行,安装过程大概5-10min,最终安装时间根据网速而定
3.下载模型
安装好之后会下载K2-fas/OmniVoice模型,但似乎国内没有镜像源导致无法下载所以出现报红提示。后面是我问了AI教我的,大家如果出现相同问题可以跟着我的步骤走或者也拿去问问AI该怎么办。
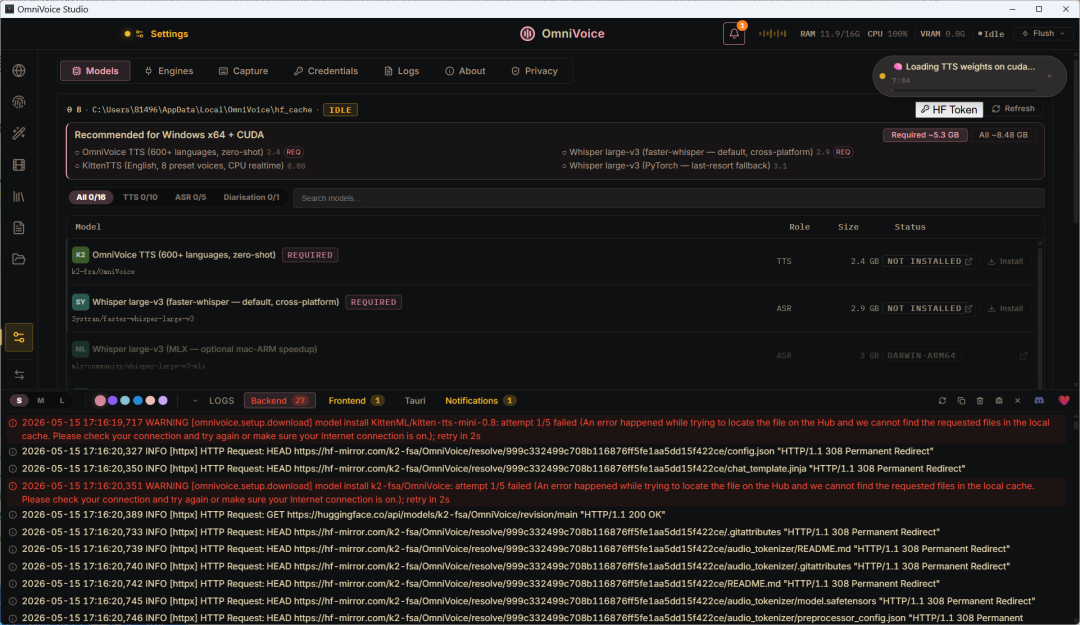
这时候我们可以先关闭OmniVoice,记得在任务管理器看看有没有残留进程,确保完全关闭。
右键点击桌面的 "此电脑" → "属性" → "高级系统设置" → "环境变量"
在 "用户变量" 中点击 "新建",添加以下两个变量之后重启电脑让变量生效:
|
|
|
|---|---|
HF_ENDPOINT |
https://hf-mirror.com |
HUGGINGFACE_HUB_CACHE |
C:Users你的用户名AppDataLocalOmniVoicehf_cache |
重启之后打开OmniVoice,就正式进入欢迎页面,会进行环境依赖和系统检查,这里告知我yt-dlp没有下载配置,这是一个youtube视频下载工具,方便直接拉取youtube视频片段进行音频生成,这里我暂时用不上选择不安装,不装yt-dlp也不会影响主要功能使用,就暂时不管直接点击continue了。
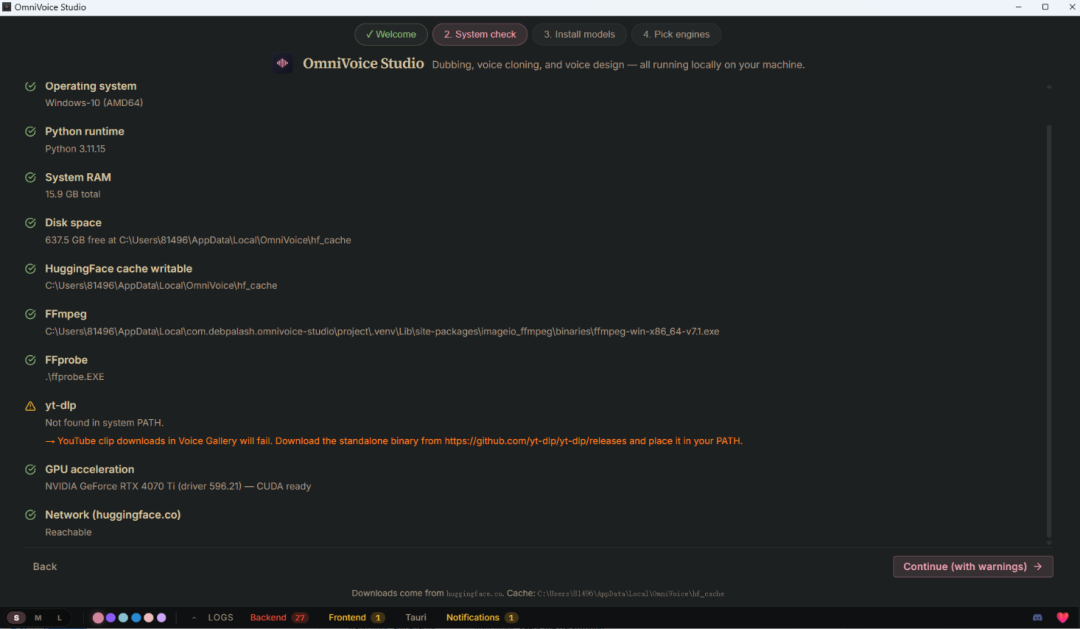
然后就来到了模型下载界面,K2OmniVoice TTS (600+ languages, zero-shot)和SYWhisper large-v3 (faster-whisper — default, cross-platform)这两个模型是核心必装模型,点击右侧install进行下载
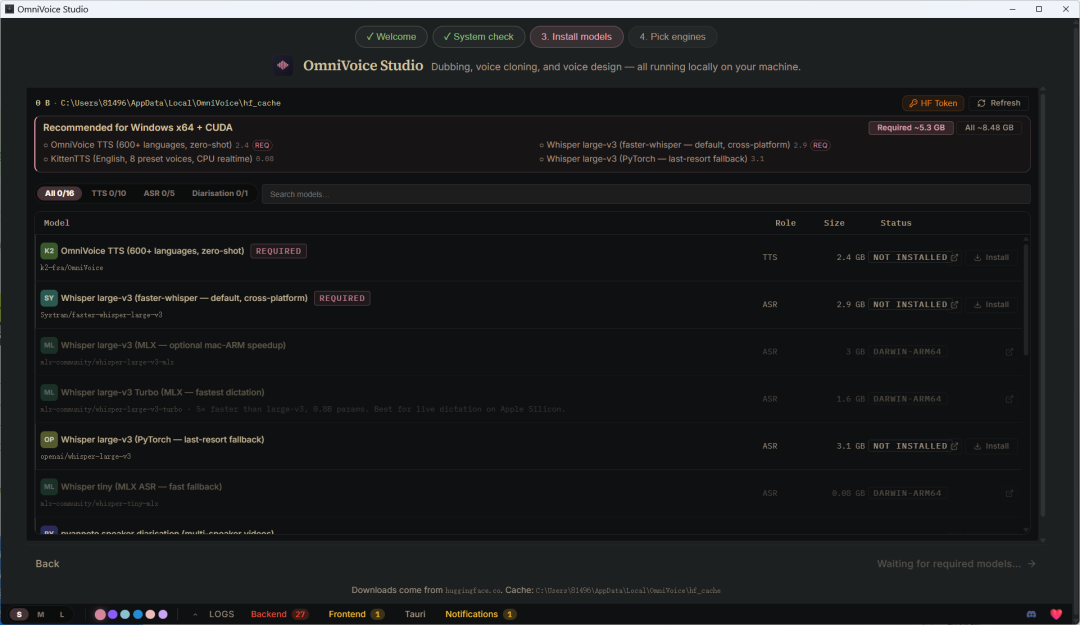
这里由于网络问题大概率会下载失败,也别内耗,自己去手动下载还得建立文件夹,我们直接调用本地的Claude Code或者Hermes,让AI自己来完成这项任务,这里给AI的提示词一定要让它读官方这两个模型的文件夹路径架构,再让它帮你下载好之后创建好文件夹把模型放进去
#一定让AI参考下面两个模型的文件安装路径https://huggingface.co/k2-fsa/OmniVoicehttps://huggingface.co/Systran/faster-whisper-large-v3
如果自己下的话可以参考下面这两张图,看上去还是比较麻烦,我是让hermes接管了这个棘手的事情。
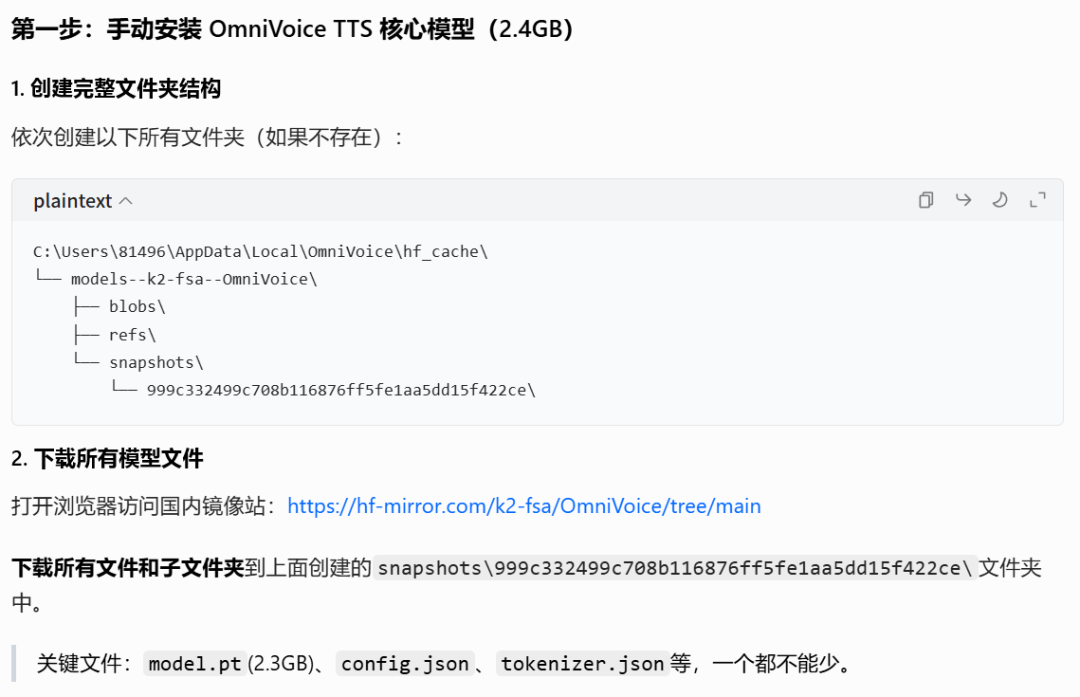
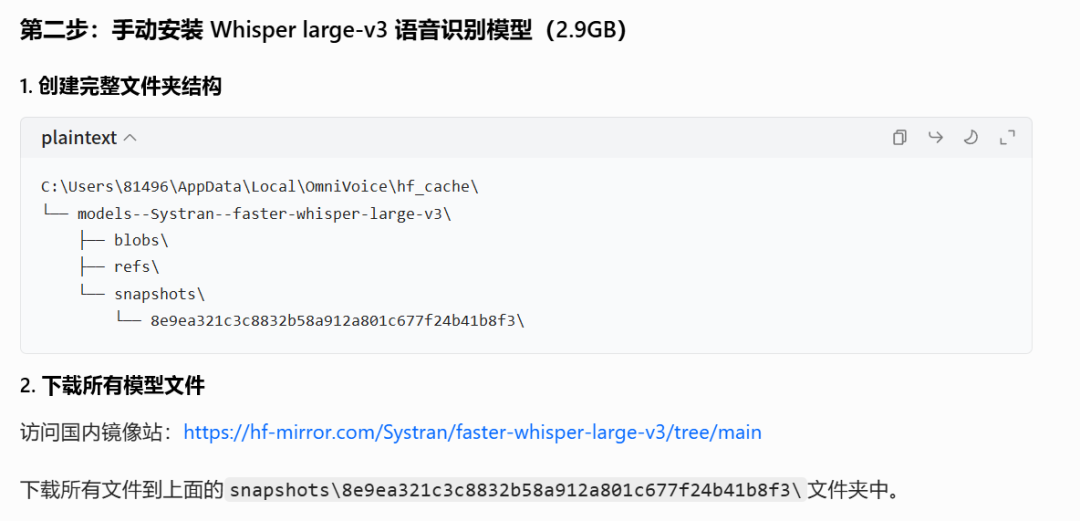
模型安装好之后就大功告成啦!
4.开测
开测前看看有哪些功能
坦率的讲,功能多到让我有点懵,这里我们就不一一测试了,今天就先测试语音克隆和配音设计这两个板块。

第一大杀器是语音克隆。你只需要给它一段3秒钟的音频,它就能把你的声音复制下来。注意,是三秒,不是三十秒,不是一分钟。三秒钟的音频,然后你就可以用这个声音去生成任意的文本朗读了。
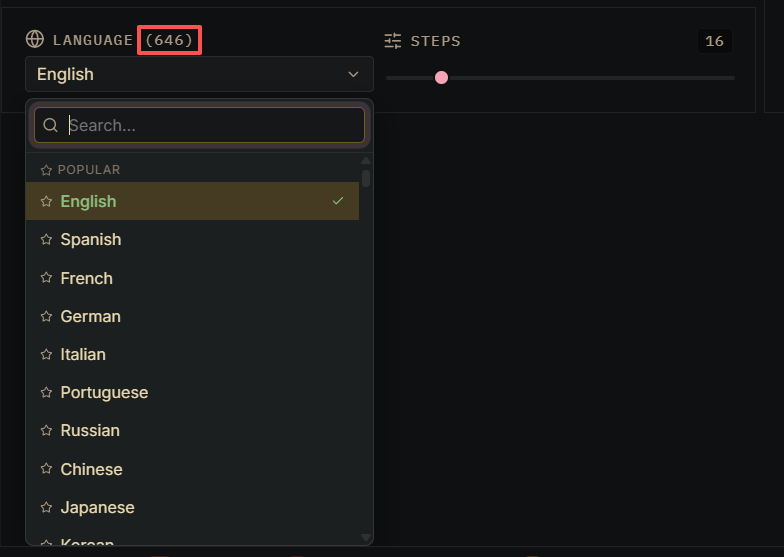
而且它支持646种语言。

646种。
ElevenLabs才支持多少种,32种。
不是说ElevenLabs不好。ElevenLabs在语音质量上目前依然是行业标杆,这点得承认。但是在语言覆盖这件事上,OmniVoice Studio直接把差距拉到了一个我一眼看过去都不知道该说什么的程度。646种语言,说实话你让我说出30种我可能都够呛。
进软件看了,真的是646种
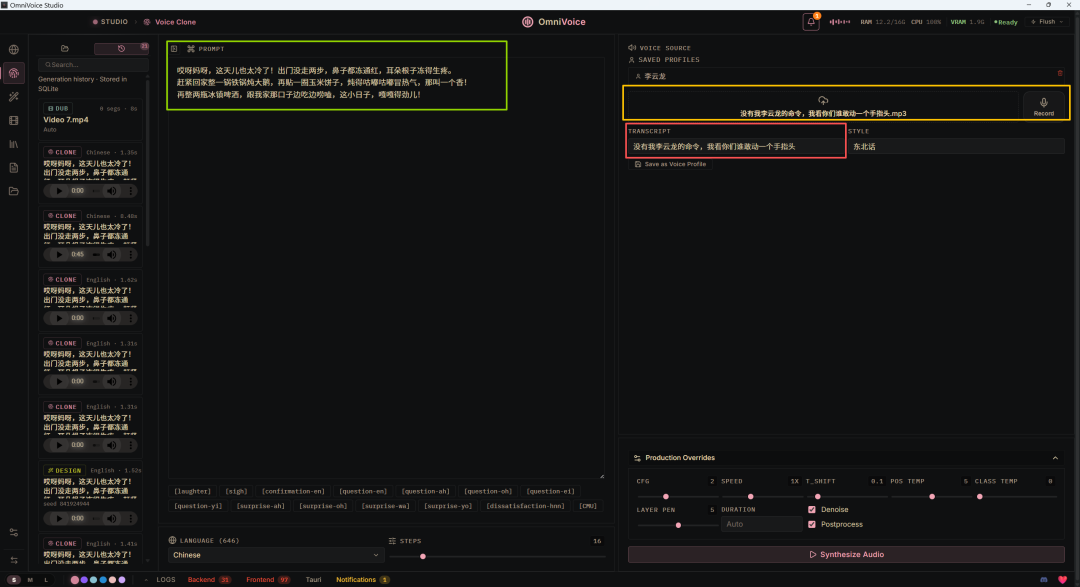
测试了一下克隆的效果,给到人上人
注意:
在黄框处选择需要克隆的声音,也可以开麦录制
在红框处写下你上传的克隆音频中的准确文字内容,这一步虽然是可选但强烈建议开启,有助于AI掌握需要克隆的声音。
在绿框处写在被克隆声音需要朗读的文字内容,你写什么AI就念什么。
测试结果:
然后是语音设计。如果说语音克隆是「复制一个已有的声音」,那语音设计就是「从零捏一个不存在的声音」。你可以调性别、年龄、口音、音高、语速、情绪,甚至方言。
这里我们让OmniVoice Studio给我们根据文本生成一段四川方言,我加入了两个语气控制,然后就只在上方选择了四川话的选项。
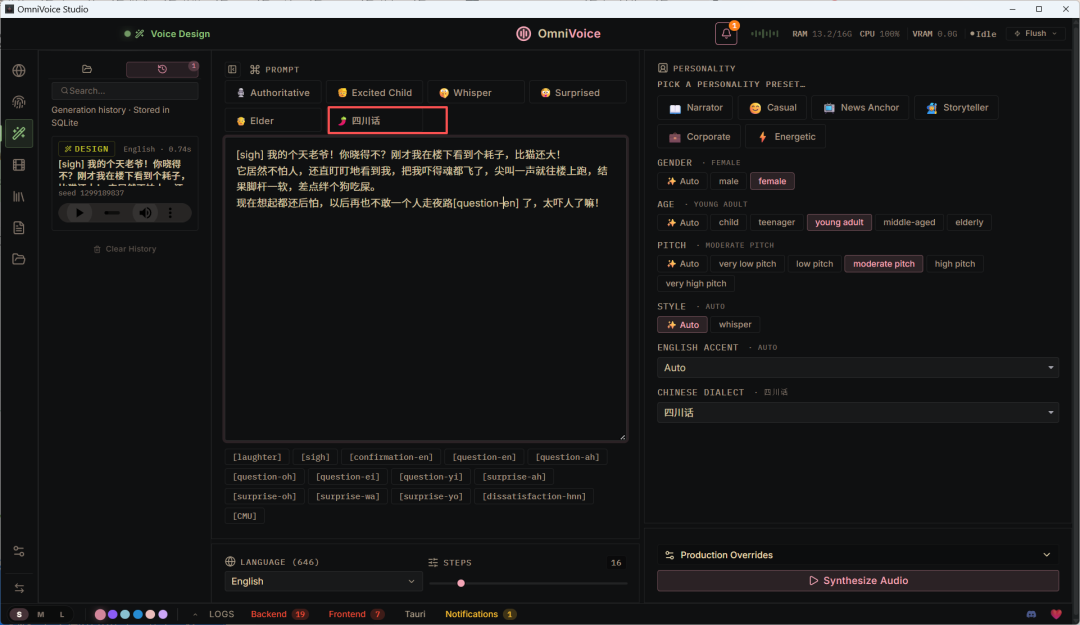
语音设计这个功能的概念不新,ElevenLabs也有。但OmniVoice Studio把它做成了一个可视化的界面,你拖拽几个滑块,声音就变了。我试想了一下那个体验,应该跟捏脸差不多,挺上头的。
这里测试了一条完全自动化的例子,从配音到语气到音调,
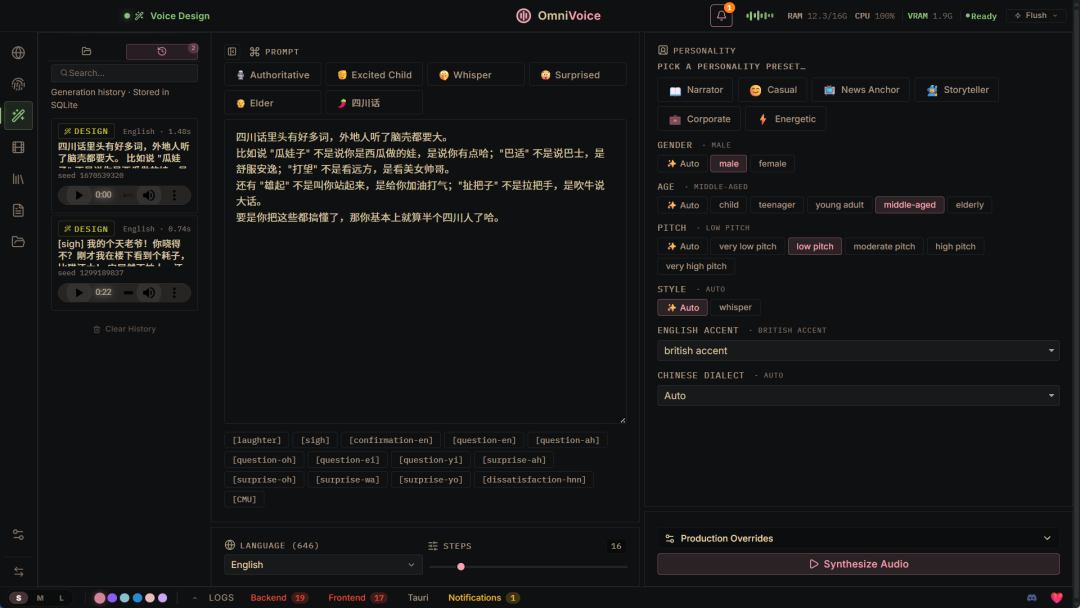
除了四川话,官方还原生支持以下咱们国家的方言:
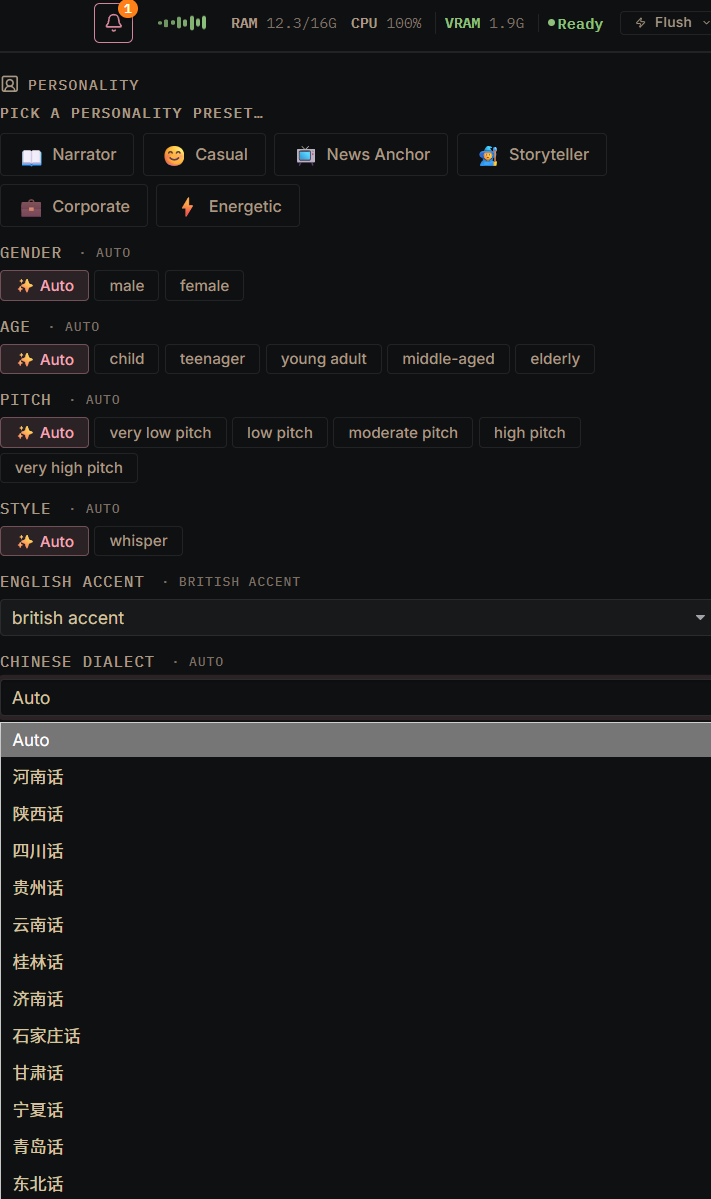
测试了一条东北话看看效果,配置如下图:
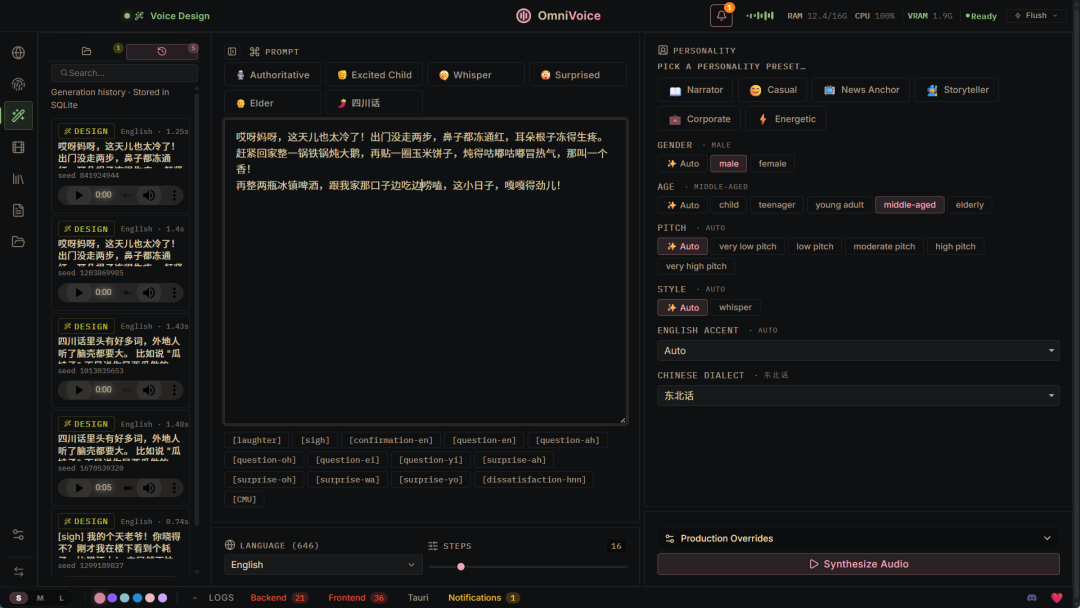
总结下,这几次测试下来给我最大的感觉就是快,基本上是秒生成,我刚点击运行呢就已经在播放配好的音了...而且效果也不错,因为我基本上都是直出,不爱调参,感觉调试下参数抽抽卡应该能达成更好的效果。
然后是视频配音。
这个功能我觉得可能是很多内容创作者的刚需。
你把一个视频拖进去,或者直接贴一个YouTube链接,它自动做四件事:先把语音转成文字,然后翻译成你选的目标语言,再用你克隆好的声音去重新生成配音,最后把新配音和视频合成一个MP4导出来。
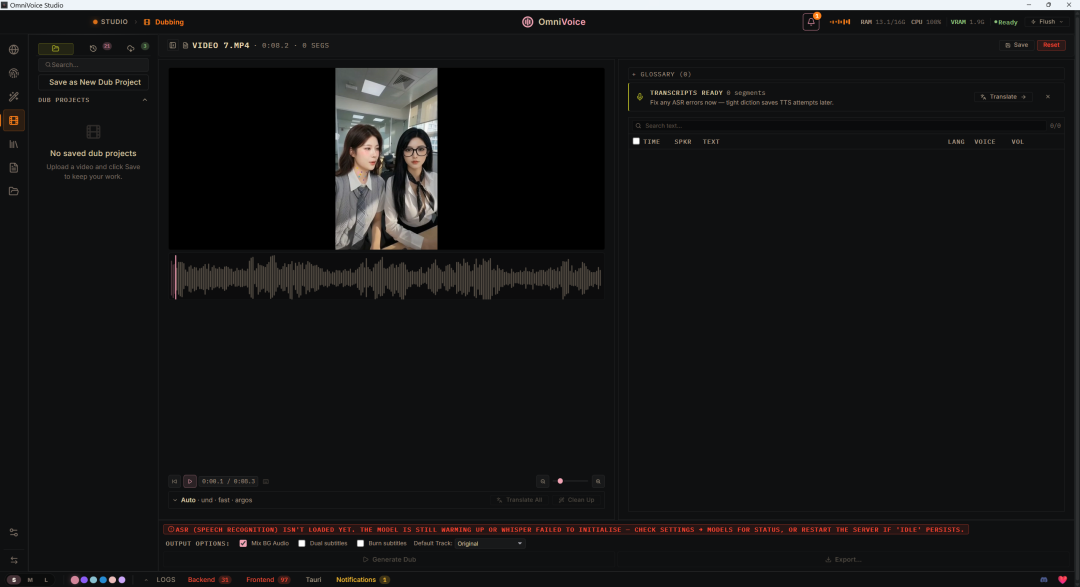
全程自动,不需要你手动对时间轴。
而且它内置了说话人识别。就是如果视频里有两个人对话,它能自动识别出谁说了什么,然后给每个人分配不同的克隆声音。
这个功能叫什么来着,Speaker Diarization。说实话这个词我每次念都觉得舌头要打结,但它做的事非常好理解,就是把「这个人说了这句,那个人说了那句」自动分清楚。
结合语音克隆,你理论上可以做到:把一个中文采访视频,自动翻译成英文,而且主持人用主持人的声音说英文,嘉宾用嘉宾的声音说英文。
这里由于我模型配置报红暂且搁置这项测试 。
。
但是这项功能,我作为内容创作者,我的第一反应是:这能省多少事儿啊。
还有一个小功能我特别喜欢。
它有一个叫Dictation Widget的东西。你按一个全局快捷键,会弹出一个浮窗,你说完话它会自动识别成文字然后粘贴到你当前光标的位置。
什么意思呢,就是你在任何一个软件里,Word也好微信也好VSCode也好,按下快捷键,说话,文字就自动输入进去了。
这个功能说实话跟ElevenLabs没什么关系,但它是那种「一旦用上了就回不去」的东西。
为什么这样的工具,之前没有人做出来。
ElevenLabs是按字计费的,最便宜的套餐一个月5美元,最贵的商业套餐330美元。而且你的所有音频都要上传到他们的服务器上处理。
OmniVoice Studio的方案是,所有的事情都在你自己的电脑上跑。不需要注册账号,不需要API Key,不需要联网。
你的声音就是你的声音,不会传到任何人的服务器上。
这个区别,我觉得已经不是「便宜和贵」的问题了,而是两种完全不同的理念。
一个是「你付钱,我用云计算帮你处理」。一个是「我把能力给你,你在自己的机器上搞定一切」。
在这里说一句啊开源yyds!
OmniVoice Studio的系统要求也不高,8GB内存,4GB显存就能跑。如果你显存不够8GB,它会自动把一部分模型放到CPU上去跑,不让你报错。如果你连显卡都没有,纯CPU也能跑,就是慢一点。
当然,这个东西也不是没缺点。
首先,它现在还在beta阶段,作者自己都在README里写了,版本之间可能会有breaking changes。你要是拿来干正事儿,可能得谨慎点。

其次,第一次启动的时候要下载大约2.4GB的模型文件,而且是从HuggingFace拉下来的。国内用户第一次启动大概率会比较慢。建议提前配个HF_TOKEN。
再者,ElevenLabs在语音的自然度和情感表达上,目前还是略胜一筹的。毕竟人家是商业公司,砸了几千万美元搞研发。OmniVoice Studio的质量在同类型开源项目里已经是顶尖水平,而且有图像界面,但要说完美平替,我觉得还差那么一口气。
不过考虑到这玩意才做了一个多月,这个完成度已经很吓人了。
还有一个细节我觉得挺值得说的。OmniVoice Studio的底层语音引擎也是开源的,叫OmniVoice,来自k2-fsa团队。项目本身用的也是MIT/Apache这种宽松协议。但OmniVoice Studio自己的许可是FSL-1.1-ALv2,个人和非商业使用免费,每个版本发布两年后自动转成Apache 2.0。
这个许可策略挺聪明的。既保护了作者的商业利益,又没有把门关死。两年之后,你的付费用户也能享受Apache 2.0的完全自由。这种「先收一点,最终全放」的思路,我觉得比很多开源项目的许可设计要务实得多。
回到这件事本身,我为什么会为一个语音工具写这么多字呢。
因为我觉得它代表了一种我特别想看到的趋势。
AI的能力不应该只掌握在少数几家收了天价订阅费的公司手里。不应该只有付得起330美元一个月的人才能用上顶级的语音AI。不应该把每个人的声音数据都上传到别人的服务器上。
OmniVoice Studio让我看到的是,那些曾经“高高在上”需要企业级才能部署的AI能力,正在走入寻常百姓家。
646种语言。
三秒克隆。
一键视频翻译配音。
全在你的电脑上跑。
一个月之前这些东西还需要花大价钱买ElevenLabs的会员。
现在你只需要一个GitHub账号,下载一个安装包,等它下载完模型,然后你就可以开始了。
这种感觉太爽了。
项目地址我再放一遍:github.com/debpalash/OmniVoice-Studio
如果你有独立显卡,真心建议去试一下。没有显卡也不要紧,CPU也能跑,就是慢点。
行了,今天就聊到这。如果安装过程有任何问题,欢迎留言讨论!
AI不硬核,把复杂AI,讲给普通人听。